Dealing With Large Features in Git Repos

There is not a "correct" way to organize your servers and git repos and each company has its own problem and solutions. Some companies use test servers to run some very basic verifications in their codebase before deploying new features to production. Some even have a staging server that is as similar to production as possible, where new features are tested for a last time before deploying to prod. Those servers usually run deployed code that is in the development, staging, and master/main branches in the git repo.
This would be what the usual flow of development looks like:

Dealing with Bugs in Tests


This works well because now Feat.1 can take as long as needed to be fixed, if any other Feature has a bug discovered we just revert it, and development can continue. Also, all the versions on all servers have the same code (which means, v1.0.3 in staging is the same as v1.0.3 in development).
What is the problem then? Well, when Feat.1 is done, we have to revert the revert. And our history becomes a mess. Imagine what it would look like if Feat.2 and 3 also did reverts?
There is one other option that works with many costs. We cherry-pick the contents of the development branch into staging.
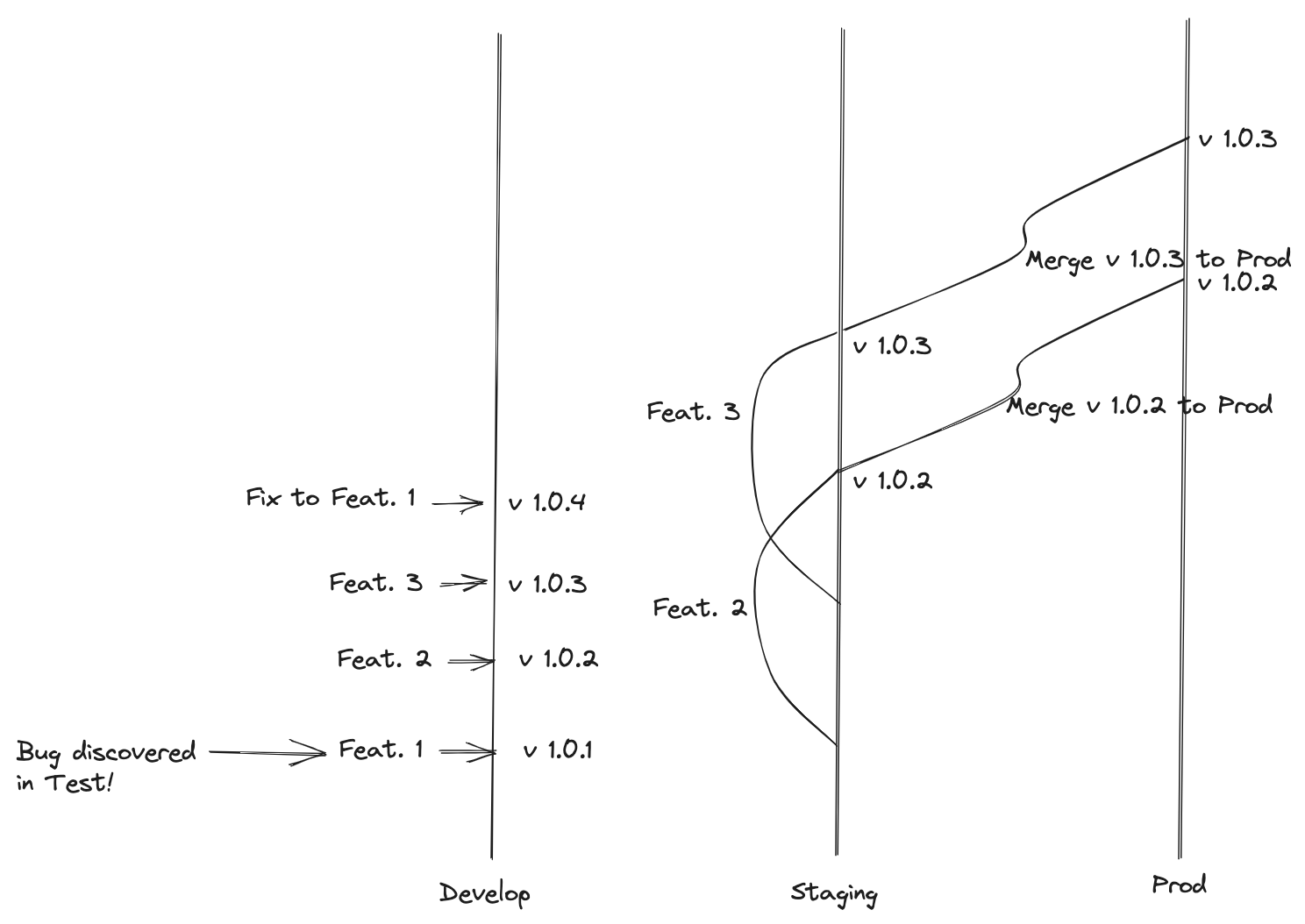
Now this one comes with a bunch of requirements to work. Let me point out a short list of things to be careful when going in this direction:
- When developing your feature branch, you must not merge the parent branch regularly (only when you are going to merge). This adds a risk that your feature branch and the parent branch will be very different when you merge, and your code will need a lot of adaptations to be merged.
- You must not squash the commits when merging to the parent branch. Otherwise, cherry-picking will be almost impossible.
- The version number in development no longer guarantees it has the same code in staging and prod. Notice that v1.0.2 in the development branch has Feat.2 and the faulty implementation of Feat.1, whereas v1.0.2 in staging only has Feat.2.
- Code in staging might become very different than code in develop over time. One thing to consider is to merge staging --> development on a regular basis.
Alternatives for Testing Large Features
Finally, for very large features that we expect to find many bugs when testing, we can consider another approach: deploying a branch in a separate server and running tests there. You can configure this server to use all the dependencies ( database, storage, redis cache, etc) of the test server.

This works great and keeps our repo clean because you will only deploy to development once it has already been tested by the test team, with the extra cost of having to configure any other tool or client we use for our test with the new server endpoint.
What are the cons? Besides the extra configuration for the test team, there is an extra cost for the new server. Also, if you do not have a pipeline ready to deploy it, there is the extra work of deploying it correctly. Basically: more work to do for this to work.
Conclusions
There is no "best" way of handling bugs found in tests. As a team, you have to figure out the approach that best suits the moment. If you have time, not very large features being developed, stuff that hardly has bugs or that bugs will be easily fixed, just wait for the fixes and deploy it. If the time to fix the issue is not clear, you have to choose between cherry-picking and reverting.
Notice that a great advantage here would be knowing in advance if the feature implementation is large/complicated/has high story points or not. That is one good use of those estimated story points in sprint planning. 😉



Comments
Post a Comment